|
I am currently a first-year Master's student at Tianjin University, supervised by Prof. Changqing Zhang. I received my Bachelor's degree in Computer Science and Technology from Tianjin University in 2025. My research focuses on LLM reasoning reinforcement (RLVR) and test-time training (TTT), including: 1) self-rewarding mechanisms for large reasoning model optimization (under review); 2) test-time training (ICLR'25). |

|
|
[2025-01] One paper accepted by ICLR, thanks to all co-authors! |
|
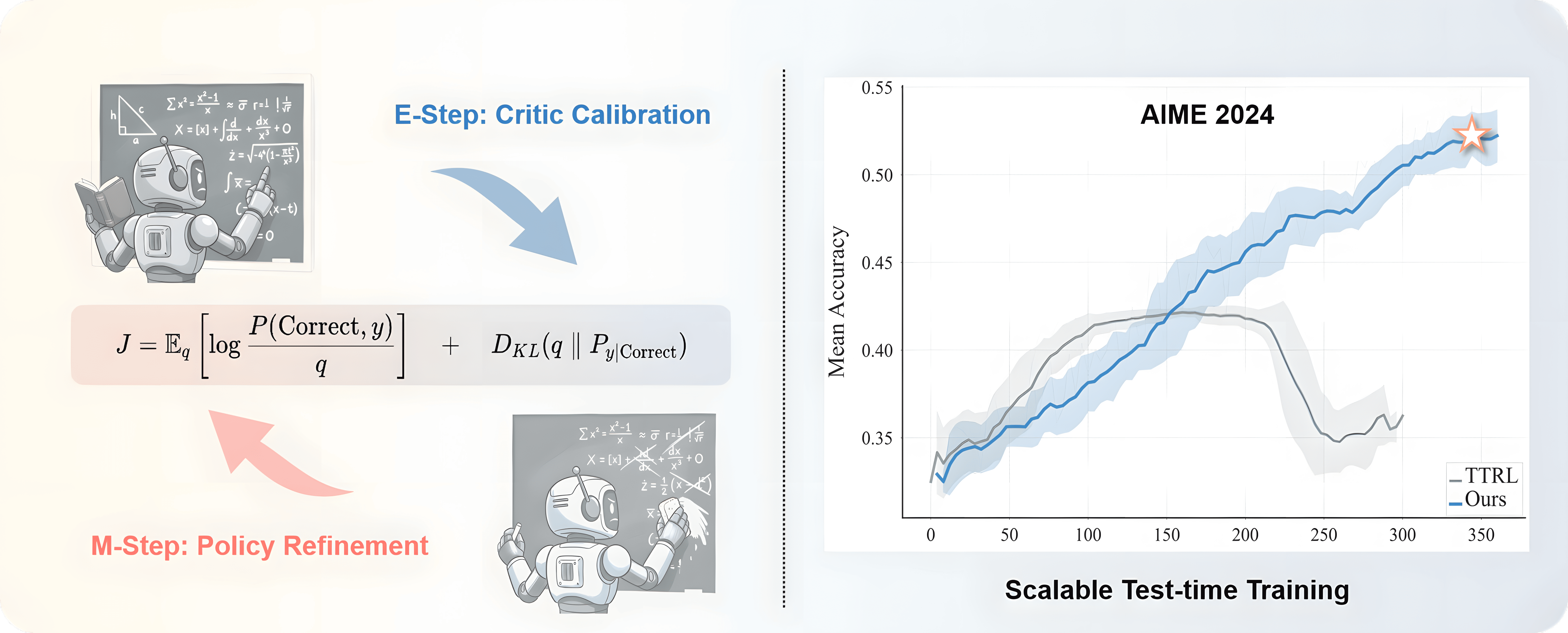
Qingyang Zhang*, Xinke Kong*, Haitao Wu, Qinghua Hu, Minghao Wu, Baosong Yang, Yu Cheng, Yun Luo, Ganqu Cui, Changqing Zhang NeurIPS, 2026 (under review) arXiv / code An EM-based test-time training framework that alternates Critic calibration (E-step) and policy optimization (M-step), enabling reasoning LLMs to keep improving post-deployment with sustained gains over 350+ steps. |
|
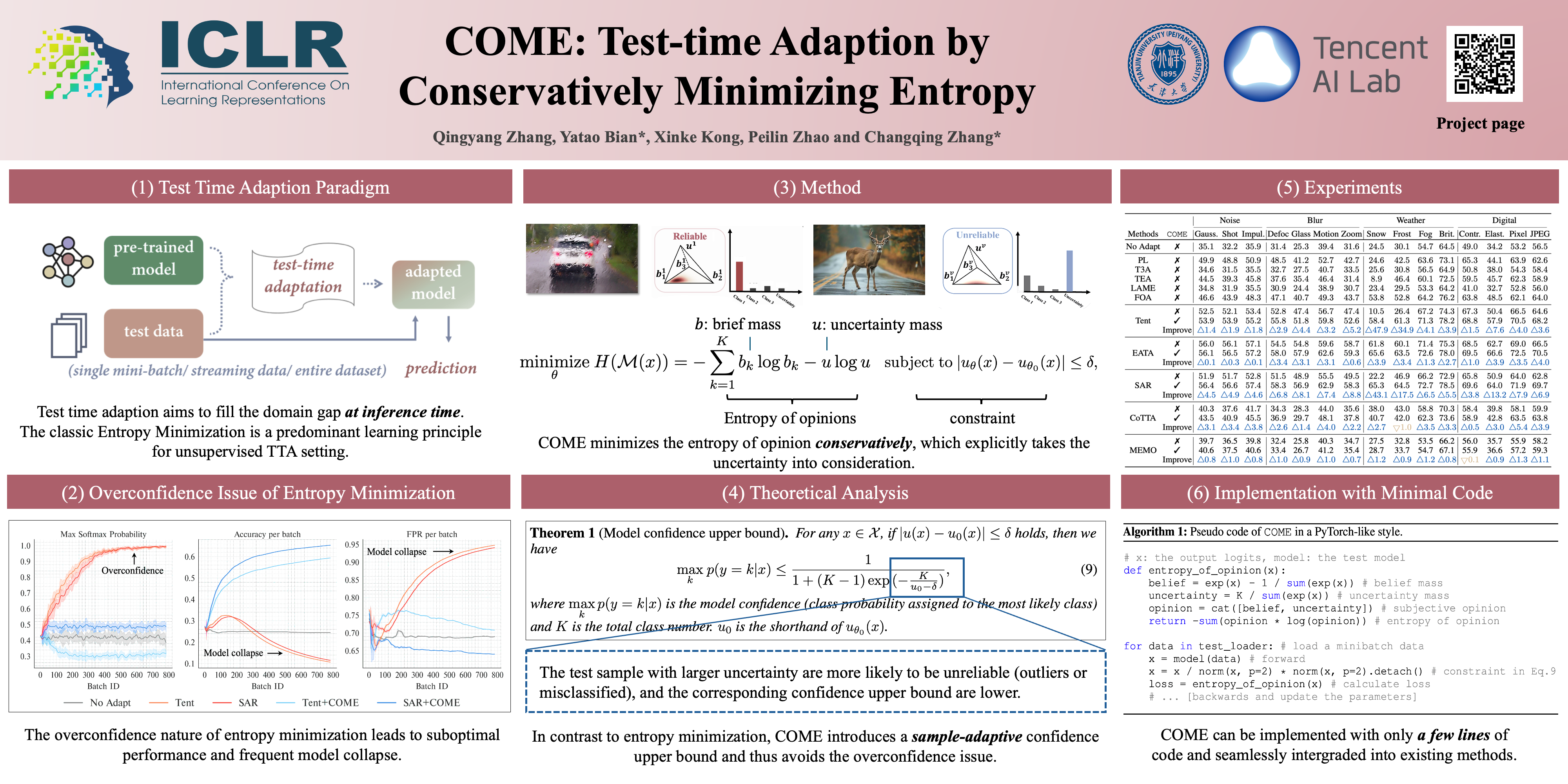
Qingyang Zhang, Yatao Bian, Xinke Kong, Peilin Zhao, Changqing Zhang ICLR, 2025 arXiv / code A conservative entropy minimization approach for test-time adaptation that explicitly models prediction uncertainty to prevent over-confidence and avoid common collapse modes. |
|
National Scholarship (1%) 2022 |
|
Conference Reviewer: ICML 2026, NeurIPS 2026 |
|
Updated at May 2026
Thanks Jon Barron for this amazing template.
|